
.avif)
Your lead scoring model is probably lying to you.
Not maliciously. It's built on a flawed assumption - that the buyers most likely to convert are the ones most willing to identify themselves early. But think about how serious buying decisions actually happen. You research quietly for weeks. You read docs, compare options, check G2 reviews. You don't fill out a form until you're ready to talk. Your model scores that entire period at zero.
Meanwhile your SDRs are working a queue of webinar attendees.
You can't fix this by tweaking point values. The model is measuring the wrong thing.
Why traditional lead scoring fails GTM teams
Classic scoring was built for a different era. Form fill: 20 points. Email open: 5. Webinar registration: 15. It rewards self-declaration, not intent.
A VP of Revenue with an active budget and a 30-day decision window scores the same as a junior employee doing competitive research. A competitor scouting your site gets identical points to your next best customer. The model can't tell them apart because it tracks actions, not actors.
There's a second failure that's quieter and possibly worse: score decay. Models get configured once and never revisited. The behaviors that correlated with closed deals two years ago stay baked into the weights. Markets change. Buyer journeys shift. The model keeps scoring against old assumptions. By the time conversion data makes the problem obvious, you've already burned real SDR capacity chasing phantom pipeline.
What AI lead scoring actually measures
The shift isn't about adding more data points. It's about what you're measuring in the first place.
Tapistro scores behavioral sequences, ICP fit, and third-party intent signals together - not sequentially, all at once.
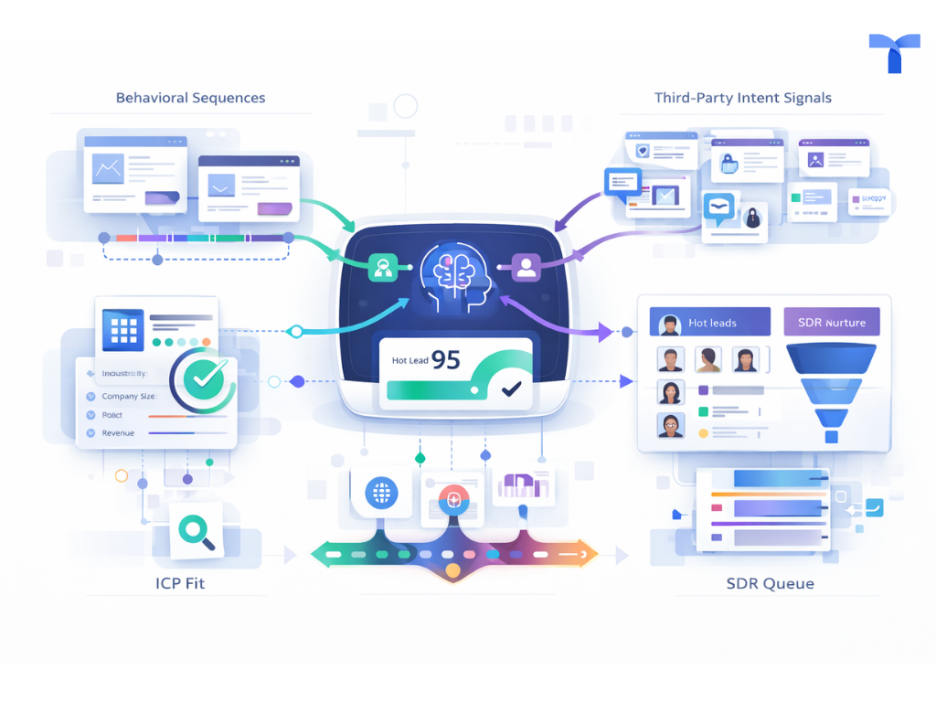
Behavioral sequences over individual actions
A prospect who moves from solution overview to pricing to integration docs in a single week is in a decision pattern. They're evaluating fit, cost, and technical requirements in the order a serious buyer actually does. The same three pages visited casually over three months mean something different, and the model knows it.
That's the core difference between AI lead scoring and the old way. One counts clicks. The other reads what those clicks mean in context.
ICP fit runs alongside intent - not after it
High intent from the wrong account is just noise. A highly engaged company from the wrong industry or wrong company size doesn't belong in the SDR queue it wastes rep time and breaks your MQL-to-SQL numbers. In Tapistro, both conditions (fit and intent) have to hold before anything escalates. The volume of leads crossing the threshold drops. The percentage converting to opportunities goes up.
Third-party intent fills the gap first-party data never can
Your website only sees buyers who already found you. What about the accounts actively researching your category, comparing you on G2, reading competitor content but haven't touched your site yet? Tapistro's intent connectors pull that research behavior into a unified account-level score. Accounts can show up as in-market before they've ever filled out a form.
A score is only useful if it triggers something
A score sitting in a dashboard is a reporting tool, not a prioritization system. Buying intent has a shelf life. If an account crosses your threshold on Tuesday and your SDR checks the queue on Friday, you've already lost timing on it.
Tapistro's AI Autopilots connect score thresholds directly to execution. When an account qualifies, an SDR task fires automatically with full context already attached: pages visited, intent signals triggered, contacts that fit the buying committee profile. No manual handoff. No one has to remember to check a dashboard.
Scores also update continuously as new signals come in not just when someone submits a form. An account sitting at moderate on Monday can cross the sales-ready threshold by Wednesday. The queue always reflects where accounts actually are right now, not a snapshot from their last declared action.
What gets better across the revenue team
For SDRs, time concentrates on accounts worth calling. Every conversation starts with context rather than cold research. The busywork of manually triaging a bloated lead list goes away.
For marketing, you can finally separate which content generates high-scoring leads from which content just generates clicks. Those are different questions that have been getting averaged together for years, and the answers should drive very different campaign decisions.
For RevOps, a forecast built on actual buyer behavior is a lot easier to defend than one built on form submission volume. And the MQL debate between sales and marketing tends to quiet down when both sides are looking at the same criteria, applied the same way, with the logic visible behind every routing decision.
Scoring was never the wrong idea
Lead scoring was a reasonable response to a real problem: too many leads, not enough SDR capacity, no systematic way to prioritize. The concept was sound. The foundation it was built on wasn't.
Points assigned to declared actions measure a buyer's comfort with self-identification. That's a narrow and unreliable proxy for purchase intent - and it systematically ignores the quiet majority doing serious evaluation before they raise their hand.
AI lead scoring changes the foundation. It measures behavioral sequences, evaluates ICP fit in parallel with intent, and extends the signal surface to cover third-party research activity that begins well before a prospect ever engages directly. The pipeline it produces is smaller in volume and higher in quality. That's the correct trade.

.png)

